Adding Secret Engine Support to vault-clj
Investing in Clojure to support core secret engine infrastructure
This post was written by Amperity summer intern Danny Rassaby after a co-op visit from Northeastern University.
During part of my internship at Amperity, I released a new major version of vault-clj, a Clojure library for interacting with Vault in a clean natively supported manner. While the release (1.0.0) has several new features, the most important is the added support for first-class secret engines.
You can think of secret engines kind of like a file system (though this is an oversimplification since they are so extensible). Just like you can mount multiple file systems on the same host OS to store and access data objects along with metadata as files, multiple secret engines can be mounted on the Vault server to store and access secrets with different metadata and properties.
Before writing KV V2, I looked at how other Vault clients implemented secret engine support. The ruby client had a particularly clean solution, taking advantage of class abstractions to allow users to have a local instances of different secret engine access points. I wanted to use a similar style of knowledge abstraction, without forcing users to interact with the complexity classes introduce (allowing abstractions more idiomatic to Clojure). Rich Hickey (the original creator of Clojure) gives a more in depth discussion of this principle in his excellent talk aptly titled Simple Made Easy. But without relying on classes, I’ll need some other simple language mechanism in Clojure for putting a whole bunch of named data (including closures) together in a single space…like a namespace!
 Pikachu finally gets Clojure namespaces.
Pikachu finally gets Clojure namespaces.
Separating different secret engine client implementations in separate namespaces allowed vault-clj to closely mirror the benefits of vault-ruby without leaving the core principles of Clojure design behind. Let’s compare the call sites:
KV V1 Secret Engine
vault-ruby, reading from a KV V1 secret store:
Vault.logical.read("superhero/avengers/falcon")
And our equivalent looks like:
(vault-kvv1/read client "superhero/avengers" "falcon")
KV V2 Secret Engine
vault-ruby, reading from a KV V2 secret store:
Vault.kv.read("superhero/avengers/falcon")
Other methods not possible on V1 secret stores are also available:
Vault.kv.read_metadata("superhero/avengers/falcon")
And our equivalent looks like:
(vault-kvv2/read client "superhero/avengers" "falcon")
(vault-kvv2/read-metadata client "superhero/avengers" "falcon")
Separation and organization of code by purpose is an overarching principle of software development that transcends individual language features. Not only does it help keep code- bases clean, but it also acts as a form of documentation for the user. Our tab autocomplete environments (like REPLs, IDEs, and most editors) can help users take advantage of this. A simple vault-kvv1/ followed by a tab will list all the possible operations on a KV V1 secret store. If instead we mixed the namespaces into a namespace called vault, a vault/ followed by a tab would list operations that a user cannot perform on a KV V1 secret store, so the onus would be on the user to discover which operations are valid.
After thinking about usability, I began to consider other design goals that are vital for good library design like extensibility, backwards compatibility, and simplicity. There are high-level concepts that remain the same between functional and imperative languages which can be used to achieve these. One of the most important is the idea of composition (which outside the restricting style of object ownership of a specific object, can be considered in terms of programming to abstractions). In vault-clj, each secret engine client calls base functionality (read/write/list/delete methods) in a core client as the diagram below shows:
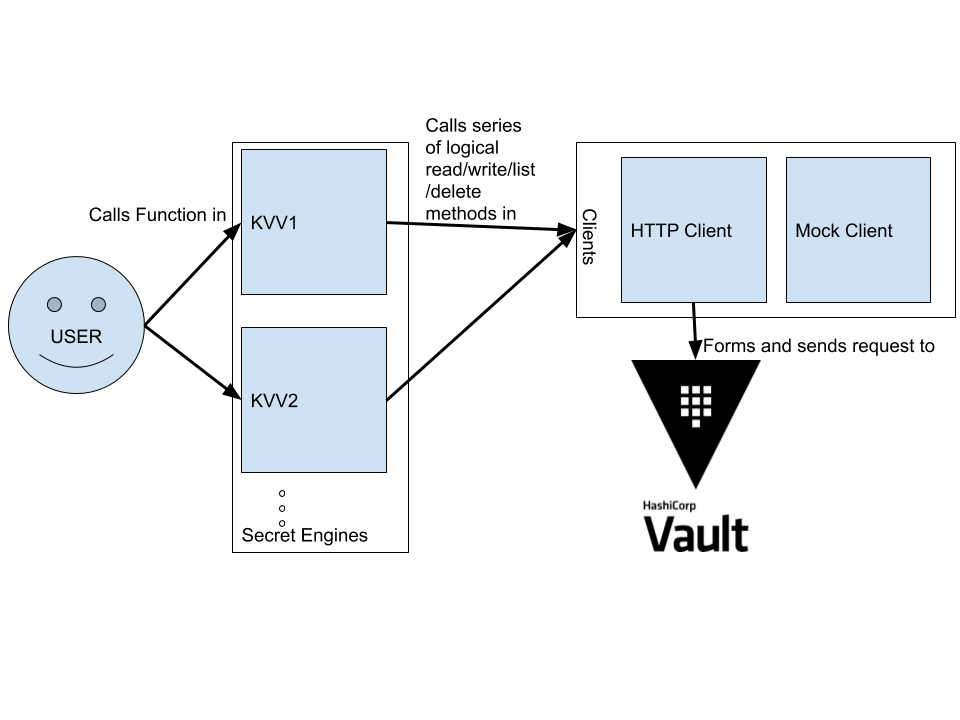 Multiple secret engine clients in vault-clj
Multiple secret engine clients in vault-clj
This helps increase maintainability by standardizing call flow throughout the program and by reducing code repetition.
I also considered goals more specific to vault-clj, like simple and extensible mocking. By consolidating core logic in the HTTP client, we can more easily mock Vault since we don’t have to special case mocking for every new secret engine we create.
This also allows mocking and core logic to be supported in the exact same fashion for extensions that add other secret engine clients without any extra work for the implementers of the extension or the end user. Even with the clear namespacing scheme I’ve implemented, adding support for every secret engine would make the code base overly cluttered. Now, less used extensions can be developed in parallel repos that pull in vault-clj as a requirement.
I’m excited to see how this project grows, and hope that vault-clj will get some community written extensions in the future.